python, db library benchmark (feat. sqlalchemy vs aiomysql)


DB 라이브러리에서 동기처리 (sqlalchemy) 가 비동기처리 (aiomysql) 특성에 따라 어떤 차이가 있는 지 살펴봤다.
벤치마크 테스트는 Pool 을 구성하고 주요 옵션이나 기능의 차이를 살펴보고자 했다.
기본적으로 동기처리는 Pool 에서 하나씩 Connection을 사용하고 리턴하는 방식으로 처리 될 것이며, 비동기 처리는 비동기로 날라오는 요청들을 가능한 Pool 안의 Connection을 가져다 쓰고 리턴하는 방식을 쓸 것이다.
1. env
- apple m1 macbook air, osx v.11.6.2 bigsur, memory 16GB
- fastapi = "0.68.2"
- SQLAlchemy = "^1.4.28"
- aiomysql = "^0.0.22"
2. 라이브러리 단순 벤치마크
1) AutoCommit, True vs False
1-1) 테스트 소스
from sys import maxsize
from sqlalchemy import create_engine
from sqlalchemy.orm import Session, sessionmaker, scoped_session
import asyncio
from faker import Faker
import time
fake = Faker('ko_kr')
LOOP = 100
POOL_MIN_SIZE = 100
# 1. AutoCommit True vs False 테스트
# 1) sqlalchemy
engine = create_engine(
'mysql://root:root@127.0.0.1:3306/test?autocommit=false',
pool_size = POOL_MIN_SIZE,
pool_recycle = 3600
)
start_time = time.time()
for i in range(LOOP):
conn = engine.connect()
name = fake.name()
address = fake.street_address()
conn.execute(
f'insert into test.test(name,address) VALUES ("{name}","{address}")'
)
conn.close()
print("[sqlalchemy] --- %s seconds ---" % round(time.time() - start_time, 5))
# -------------------------------------------------------------------------------
conn = engine.connect()
conn.execute('TRUNCATE TABLE test.test')
conn.close()
time.sleep(2)
# -------------------------------------------------------------------------------
import aiomysql
# 2) aiomysql
async def test_example():
pool = await aiomysql.create_pool(
user="root", password="root", host="127.0.0.1", db="test",
# minsize = POOL_MIN_SIZE,
# maxsize = POOL_MIN_SIZE+100,
pool_recycle = 3600,
autocommit = False
)
start_time = time.time()
for i in range(LOOP):
conn = await pool.acquire()
cur = await conn.cursor()
name = fake.name()
address = fake.street_address()
await cur.execute(
f'insert into test.test(name,address) VALUES ("{name}","{address}")'
)
await cur.close()
pool.release(conn)
print("[aiomysql] --- %s seconds ---" % round(time.time() - start_time, 5))
pool.close()
asyncio.run(test_example())
# 3) aiomysql, pool not returned
async def test_example():
pool = await aiomysql.create_pool(
user="root", password="root", host="127.0.0.1", db="test",
# minsize = POOL_MIN_SIZE,
# maxsize = POOL_MIN_SIZE+100,
pool_recycle = 3600,
autocommit = False
)
start_time = time.time()
for i in range(LOOP):
conn = await pool.acquire()
cur = await conn.cursor()
name = fake.name()
address = fake.street_address()
await cur.execute(
f'insert into test.test(name,address) VALUES ("{name}","{address}")'
)
# await cur.close()
# pool.release(conn)
print("[aiomysql (pool not returned)] --- %s seconds ---" % round(time.time() - start_time, 5))
pool.close()
asyncio.run(test_example())
1-1) AutoCommit False 설정
- sqlalchemy vs aiomysql
autocommit false 모드에서는,
동기처리 (sqlalchemy) 가 비동기처리 (aiomysql) 보다 빠르며, 비동기처리시 connection 반환에 대한 비용이 큰 것으로 보임.

1-2) AutoCommit True 설정
- sqlalchemy vs aiomysql
autocommit true 모드에서는,
동기처리 (sqlalchemy) 가 비동기처리 (aiomysql) 보다 느리며, 비동기처리시 발생했던 connection 반환에 대한 비용도 작아졌다.

2) Transaction 처리
1-1) 테스트 소스
from sys import maxsize
from sqlalchemy import create_engine
from sqlalchemy.orm import Session, sessionmaker, scoped_session
import asyncio
from faker import Faker
import time
fake = Faker('ko_kr')
LOOP = 100
POOL_MIN_SIZE = 100
# 2. Transaction 테스트
# 1) sqlalchemy
engine = create_engine(
'mysql://root:root@127.0.0.1:3306/test',
pool_size = POOL_MIN_SIZE,
pool_recycle = 3600
)
start_time = time.time()
for i in range(LOOP):
conn = engine.connect().execution_options(autocommit=False)
trans = conn.begin()
name = fake.name()
address = fake.street_address()
conn.execute(
f'insert into test.test(name,address) VALUES ("{name}","{address}")',
)
trans.commit()
conn.close()
print("[sqlalchemy] --- %s seconds ---" % round(time.time() - start_time, 5))
# -------------------------------------------------------------------------------
conn = engine.connect().execution_options(autocommit=True)
conn.execute('TRUNCATE TABLE test.test')
conn.close()
time.sleep(2)
# -------------------------------------------------------------------------------
import aiomysql
# 2) aiomysql
async def test_example():
pool = await aiomysql.create_pool(
user="root", password="root", host="127.0.0.1", db="test",
minsize = POOL_MIN_SIZE,
maxsize = POOL_MIN_SIZE+100,
pool_recycle = 3600,
autocommit = False
)
start_time = time.time()
for i in range(LOOP):
conn = await pool.acquire()
await conn.begin()
cur = await conn.cursor()
name = fake.name()
address = fake.street_address()
await cur.execute(
f'insert into test.test(name,address) VALUES ("{name}","{address}")'
)
await conn.commit()
await cur.close()
pool.release(conn)
print("[aiomysql] --- %s seconds ---" % round(time.time() - start_time, 5))
pool.close()
asyncio.run(test_example())
# 3) aiomysql, pool not returned
async def test_example():
pool = await aiomysql.create_pool(
user="root", password="root", host="127.0.0.1", db="test",
# minsize = POOL_MIN_SIZE,
# maxsize = POOL_MIN_SIZE+100,
pool_recycle = 3600,
autocommit = False
)
start_time = time.time()
for i in range(LOOP):
conn = await pool.acquire()
await conn.begin()
cur = await conn.cursor()
name = fake.name()
address = fake.street_address()
await cur.execute(
f'insert into test.test(name,address) VALUES ("{name}","{address}")'
)
await conn.commit()
# await cur.close()
# pool.release(conn)
print("[aiomysql (pool not returned)] --- %s seconds ---" % round(time.time() - start_time, 5))
pool.close()
asyncio.run(test_example())
1-2) Transaction 성능평가
Transaction 처리는 동기처리 (sqlalchemy) 가 비동기처리 (aiomysql) 보다 빠르다. 아마도 각각의 비동기 처리에 대한 부담이 더 커진 까닭일 것이다.

3. FastAPI 연동 벤치마크
지난글 (CRUD 기능구현)에서 사용한 encode 의 Databases를 거둬내고 sqlalchemy 와 aiomysql로 디비 부분만 변경하여 벤치마크 하기로 했다.
1-1) 부하 테스트 소스
10만 row 의 데이터를 DB에 넣어두고, 목록을 10개씩 불러오는 API 를 무작위로 호출한다.

from locust import HttpUser, task
import random
class MyTest(HttpUser):
@task
def index(self):
# http://127.0.0.1:8000/memo/list/10000
r = random.randint(1,10000)
self.client.get(f"/memo/list/{r}")
1) SqlAlchemy 연동 테스트 (autocommit=True)
1-1) sqlalchemy 연동, 소스
소스는 지난 글에 만들어진 것을 수정하여 사용했으며 변경된 내용은 다음과 같다.
# database.py
from os import environ
from dotenv.main import load_dotenv
from sqlalchemy import create_engine, MetaData
from sqlalchemy.orm import Session
# .env 환경파일 로드
load_dotenv()
# 디비 접속 URL
DB_CONN_URL = '{}://{}:{}@{}:{}/{}'.format(
environ['DB_TYPE'],
environ['DB_USER'],
environ['DB_PASSWD'],
environ['DB_HOST'],
environ['DB_PORT'],
environ['DB_NAME'],
)
# 모델 초기화를 위한 커넥션 부분
db_engine = create_engine(
DB_CONN_URL,
pool_size = 100,
max_overflow = 10,
pool_recycle = 3600,
)
db_metadata = MetaData()# main.py
from fastapi import FastAPI, Request
from apps.database import db_engine
from apps.memo.router import memo_router
app = FastAPI(
title="Memo API",
description="Memo CRUD API project",
version="0.0.1"
)
@app.on_event("startup")
async def startup():
db_engine.connect().execution_options(autocommit=True)
@app.on_event("shutdown")
async def shutdown():
db_engine.dispose()
@app.middleware("http")
async def state_insert(request: Request, call_next):
request.state.db_conn = db_engine
response = await call_next(request)
return response
app.include_router(memo_router)# router.py
from typing import List
from fastapi.param_functions import Depends
from fastapi.routing import APIRouter
from fastapi.requests import Request
from sqlalchemy.engine.base import Engine
# Memo 스키마
from apps.memo.schema import MemoCreate, MemoSelect
# Memo 모델
from apps.memo.model import memo
memo_router = APIRouter()
# 디비 쿼리를 위한 종속성 주입을 위한 함수
def get_db_conn(request: Request):
return request.state.db_conn
@memo_router.get("/memo/list/{page}", response_model=List[MemoSelect])
async def memo_list(
page : int = 1,
limit : int = 10,
db : Engine = Depends(get_db_conn)
):
offset = (page-1)*limit
query = memo.select().offset(offset).limit(limit)
result = db.execute(query)
return result.fetchall()
1-2) sqlalchemy 연동, 테스트 설정
- uvicorn
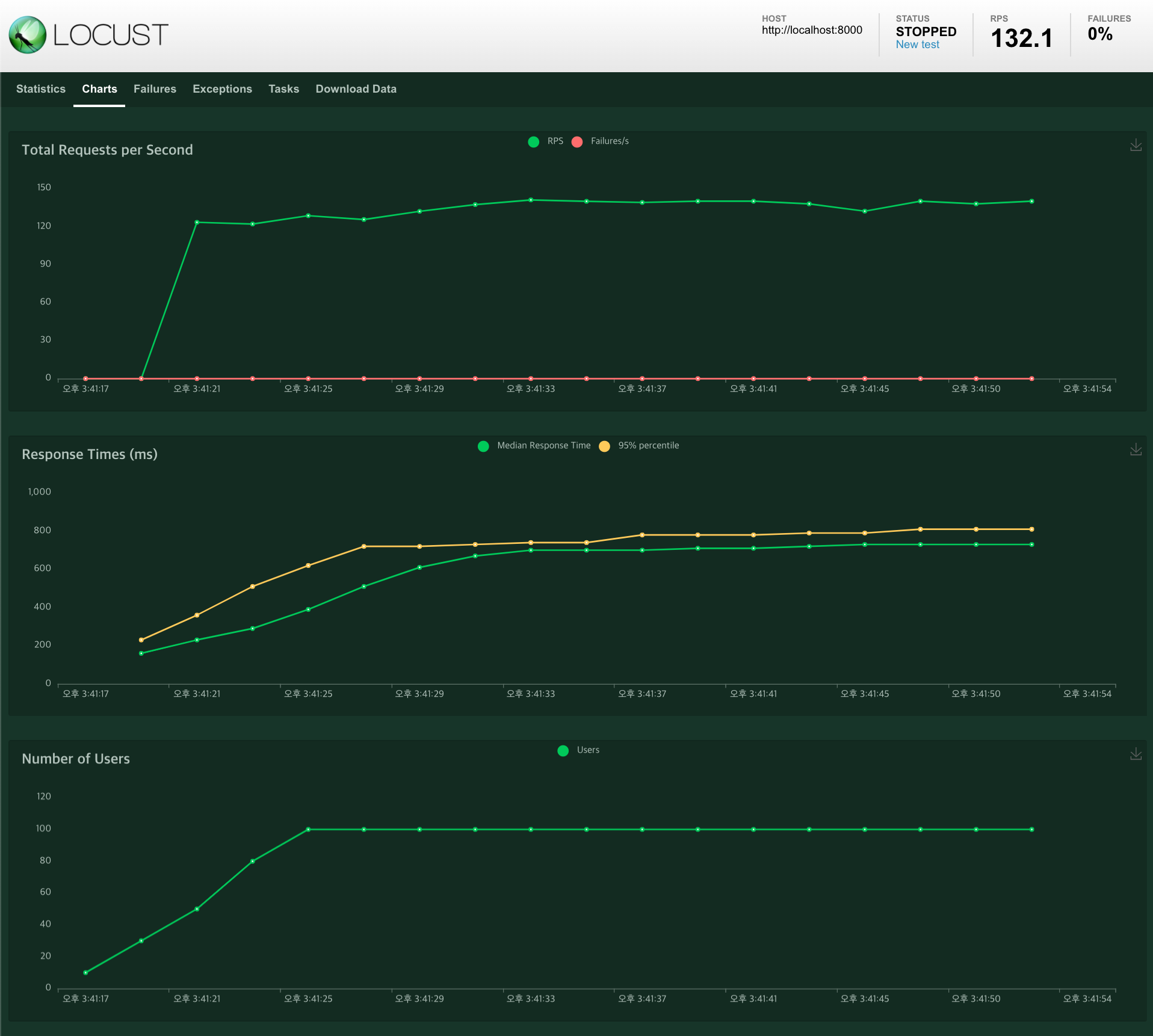
uvicorn apps.main:app --workers=1 --loop=uvloop --http httptools1-3) sqlalchemy 연동, 테스트 결과
- 최대 DB 커넥션 수 : 1
- 최대 RPS 132
2) aiomysql 연동 테스트 (autocommit=True)
1-1) aiomysql 연동, 소스
# database.py
from os import environ
from dotenv.main import load_dotenv
from sqlalchemy import create_engine, MetaData
from sqlalchemy.orm import Session
import aiomysql
import asyncio
# .env 환경파일 로드
load_dotenv()
# 디비 접속 URL
DB_CONN_URL = '{}://{}:{}@{}:{}/{}'.format(
environ['DB_TYPE'],
environ['DB_USER'],
environ['DB_PASSWD'],
environ['DB_HOST'],
environ['DB_PORT'],
environ['DB_NAME'],
)
# 모델 초기화를 위한 커넥션 부분
db_engine = create_engine(
DB_CONN_URL,
pool_size = 1,
max_overflow = 1,
pool_recycle = 3600,
)
db_metadata = MetaData()# main.py
from fastapi import FastAPI, Request
from apps.memo.router import memo_router
# from aiomysql.sa import create_engine
import aiomysql
app = FastAPI(
title="Memo API",
description="Memo CRUD API project",
version="0.0.1"
)
@app.on_event("startup")
async def startup():
app.state.db_pool = await aiomysql.create_pool(
user="root", password="root", host="127.0.0.1", db="test",
# minsize = 100,
# maxsize = 100,
pool_recycle = 3600,
autocommit = True
)
@app.on_event("shutdown")
async def shutdown():
app.state.db_pool.close()
@app.middleware("http")
async def state_insert(request: Request, call_next):
request.state.db_pool = app.state.db_pool
request.state.db_conn = await app.state.db_pool.acquire()
response = await call_next(request)
return response
app.include_router(memo_router)# router.py
from typing import Any, List
from fastapi.param_functions import Depends
from fastapi.routing import APIRouter
from fastapi.requests import Request
from sqlalchemy.sql.expression import table
from apps.memo.schema import MemoCreate, MemoSelect
from apps.memo.model import memo
from aiomysql import Pool, DictCursor
from aiomysql.sa import Engine
import aiomysql
memo_router = APIRouter()
# 디비 쿼리를 위한 종속성 주입을 위한 함수
def get_db_conn(request: Request):
pool = request.state.db_pool
db = request.state.db_conn
try:
yield db
finally:
pool.release(db)
@memo_router.get("/memo/list/{page}", response_model=List[MemoSelect])
async def memo_list(
page : int = 1,
limit : int = 10,
db : Pool = Depends(get_db_conn)
):
offset = (page-1)*limit
cur = await db.cursor(DictCursor)
await cur.execute(f'SELECT memo.idx, memo.regdate, memo.title, memo.body FROM memo limit {offset}, 10')
return await cur.fetchall()
1-2) aiomysql 연동, 테스트 설정
- uvicorn
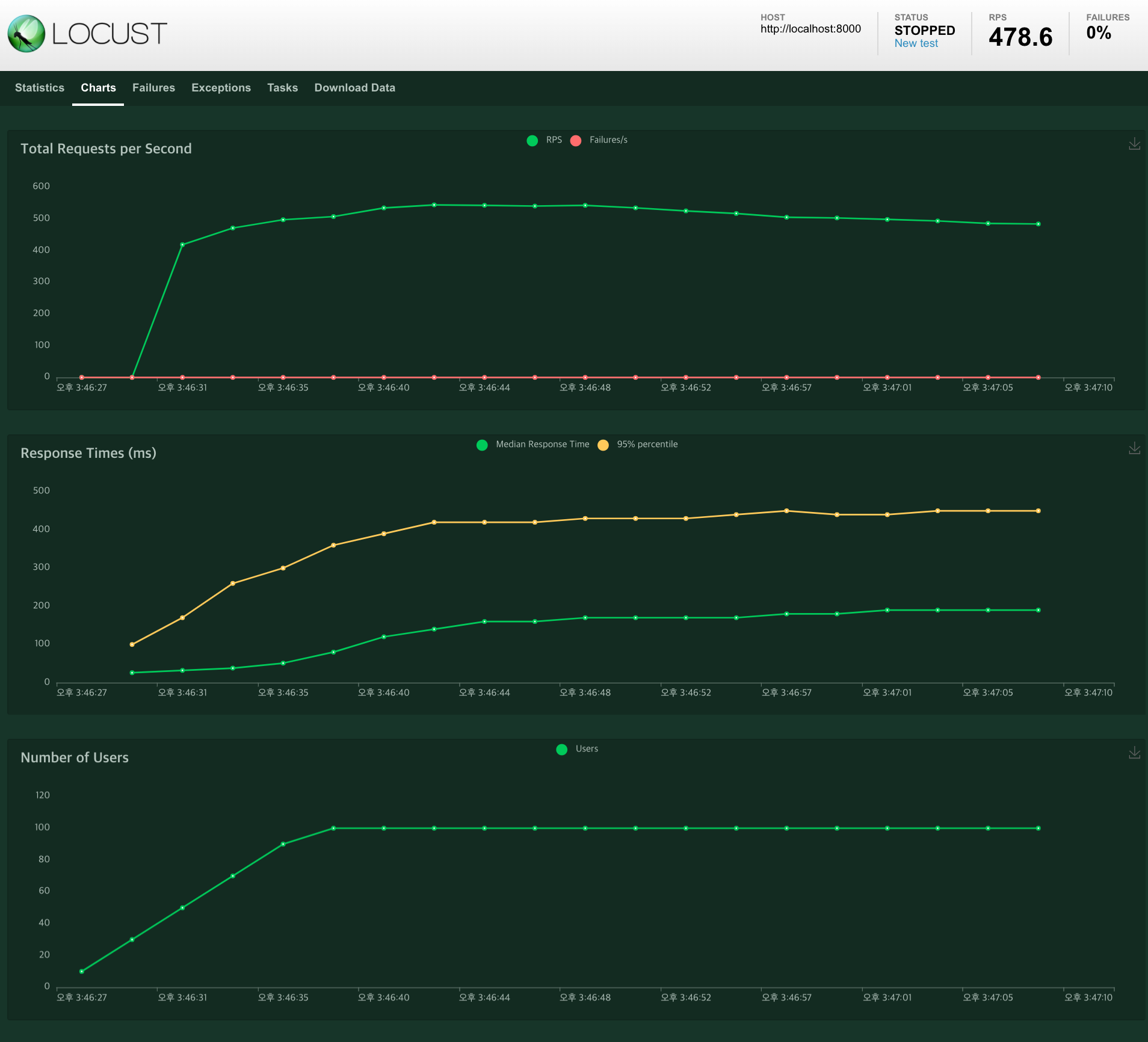
uvicorn apps.main:app --workers=1 --loop=uvloop --http httptools1-3) aiomysql 연동, 테스트 결과
- 최대 DB 커넥션 수 : 101
- 최대 RPS 478
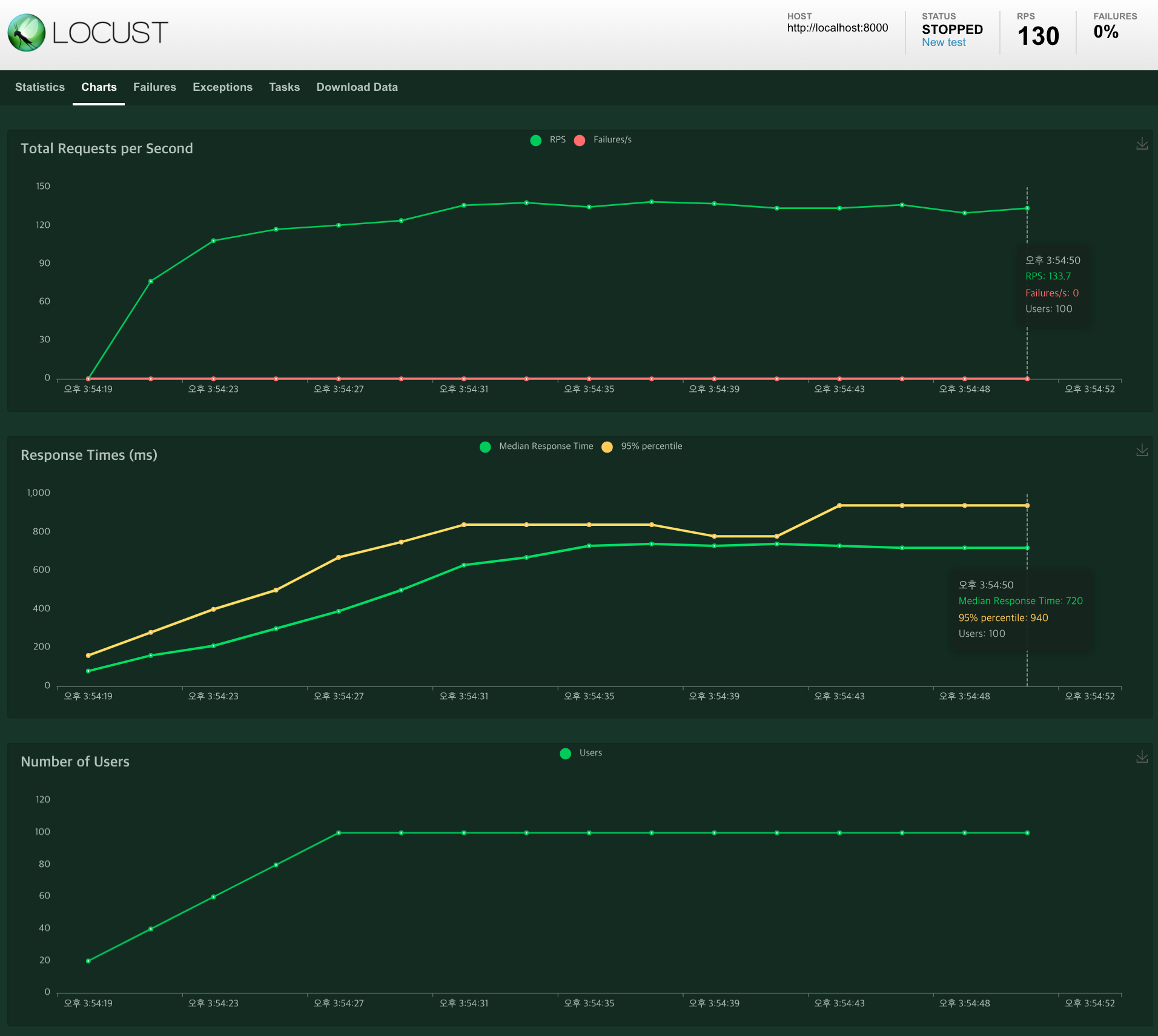
3) SqlAlchemy 연동 테스트 (autocommit=False)
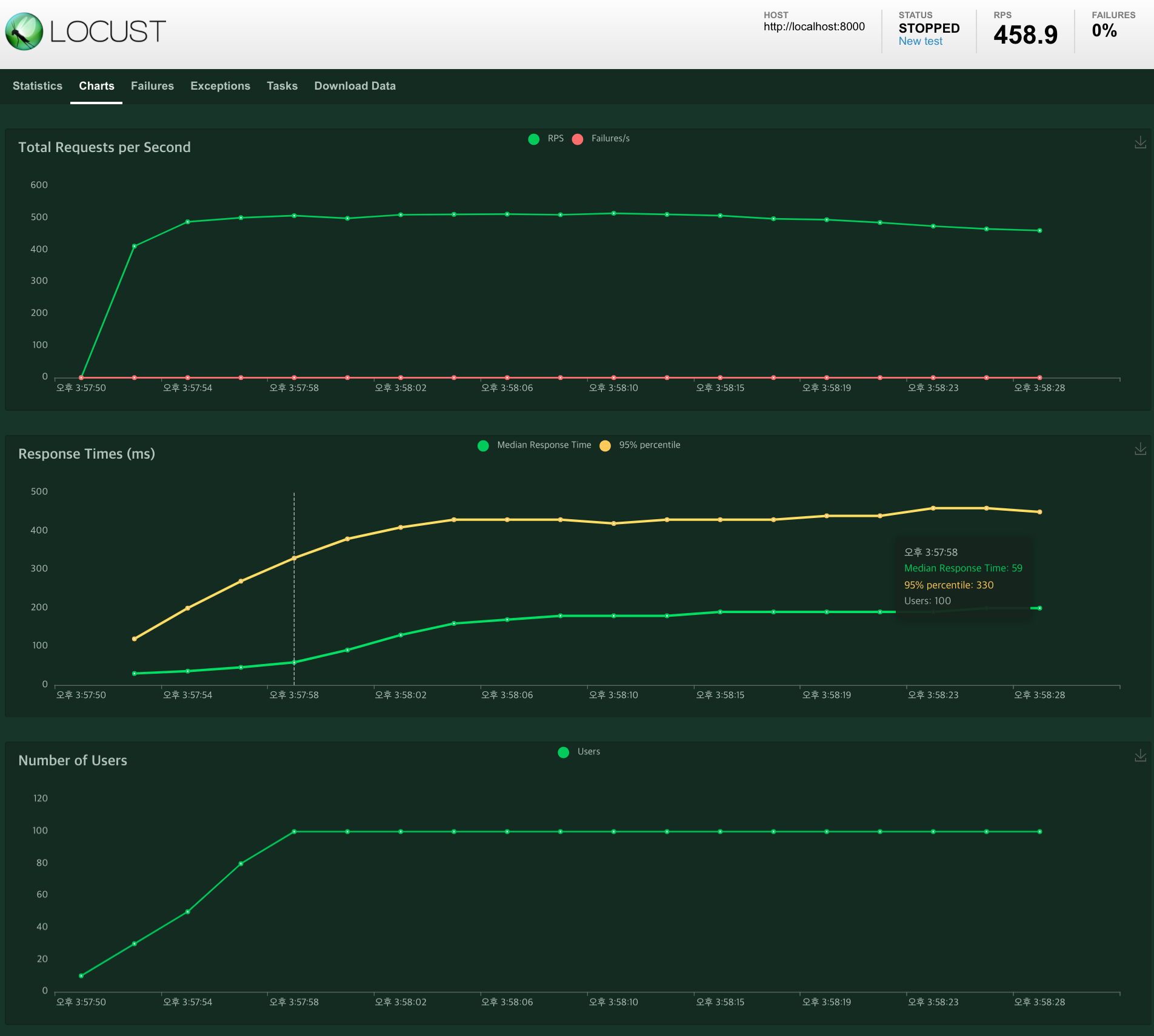
4) aiomysql 연동 테스트 (autocommit=False)
5) 결론
동기 DB라이브러리는 ASGI 프레임웍에서 커넥션풀을 제대로 활용 못하는 문제가 있어 보인다. Worker(Process)가 여러개 인 경우에도 비동기 DB라이브러리와 ASGI 프레임웍의 성능에는 못미치는 듯 하다.