Vector DB로 악플 구분하기 feat. Weaviate
Vector DB 기능을 간단히 테스트 하기 위해 혐오표현 문장을 DB 에 삽입하고, 테스트 하고자 하는 문장이 혐오표현에 가까운지 여부를 판단하는 코드를 작성해본다.


Vector DB 기능을 간단히 테스트 하기 위해 혐오표현 문장을 DB 에 삽입하고, 테스트 하고자 하는 문장이 혐오표현에 가까운지 여부를 판단하는 코드를 작성해본다.
1. 한글 혐오표현 구분
1) Vector DB, Weaviate 설치
Weaviate 를 설치하고 한글 벡터처리를 위해 openai 를 사용하기로 했다.
version: '3.4'
services:
weaviate:
command:
- --host
- 0.0.0.0
- --port
- '8080'
- --scheme
- http
image: semitechnologies/weaviate:1.20.5
ports:
- 8080:8080
restart: on-failure:0
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
CLUSTER_HOSTNAME: 'node1'
DEFAULT_VECTORIZER_MODULE: 'text2vec-openai'
ENABLE_MODULES: 'text2vec-openai'
OPENAI_APIKEY: 'sk-????????????????????????????????????'2) Weaviate 데이터 스키마 구성
한글 테스트 데이터셋은 스마일게이트에서 공개한 혐오표현 데이터를 사용하기로 한다
 smilegate-ai
smilegate-aiimport pandas as pd
import json
df = pd.read_csv("./unsmile_train_v1.0.tsv", sep='\t')
from weaviate import Client
client = Client("http://localhost:8080")
client.schema.create_class({
"class": "HateSpeech",
"description": "HateSpeech Collection",
"properties": [
{
"dataType": ["text"],
"name": "speech",
},
{
"dataType": ["int"],
"name": "clean",
},
],
"vectorizer": "text2vec-openai",
})3) 데이터 삽입
# 데이터 정리
schemas = []
for idx in range(len(df)):
item = df.iloc[idx]
speech = str(item['문장']).strip().lower()
clean = str(item['clean'])
schemas.append({
"speech" : speech,
"clean": 1 if clean == '1' else 0,
})
# OpenAI 에서 Vector 값 받아 Insert
with client.batch(
batch_size=200,
num_workers=1,
dynamic=True
) as batch:
for k, v in enumerate(schemas):
res = client.batch.add_data_object(
v, "HateSpeech",
)
print(k)
print(v)
time.sleep(5)
# 문장 체크
def check(text):
return client.query.get("HateSpeech", ["clean"]).with_near_text({"concepts": [
text
],'certainty': 0.7}).with_limit(1).with_additional(["distance"]).do()4) 한글 혐오표현 구분 테스트
clean 값이 0인 경우가 혐오표현으로 판단된 문장인데, 노골적인 문장을 제외하고 몇몇 문장은 오탐을 하는 경우도 있었다.
뒤늦게 생각해보니 weaviate 는 문장을 넣을때 문장을 tokenize 해서 벡터화 하고 있을까 하는 의문이 들었다.

2. 영문 혐오표현 구분
1) Weaviate, Vector Module 변경
weaviate 는 다양한 Vector Module 을 제공하고 있다.


한글 벡터는 OpenAI 또는 Huggingface 를 써야 하는데 call limit 이 있어서 로컬에서 편하게 사용할 수 있는 text2vec-contextionary 를 쓰기로 했고 다음과 같이 세팅한다.
version: '3.4'
services:
weaviate:
command:
- --host
- 0.0.0.0
- --port
- '8080'
- --scheme
- http
image: semitechnologies/weaviate:1.20.5
ports:
- 8080:8080
restart: on-failure:0
environment:
CONTEXTIONARY_URL: contextionary:9999
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: './data'
DEFAULT_VECTORIZER_MODULE: 'text2vec-contextionary'
ENABLE_MODULES: 'text2vec-contextionary'
CLUSTER_HOSTNAME: 'node1'
contextionary:
environment:
OCCURRENCE_WEIGHT_LINEAR_FACTOR: 0.75
EXTENSIONS_STORAGE_MODE: weaviate
EXTENSIONS_STORAGE_ORIGIN: http://weaviate:8080
NEIGHBOR_OCCURRENCE_IGNORE_PERCENTILE: 5
ENABLE_COMPOUND_SPLITTING: 'false'
image: semitechnologies/contextionary:en0.16.0-v1.0.2
ports:
- 9999:9999로컬에서 한글을 Vector Module 을 사용하고 싶은 경우는 text2vec-transformer 를 사용하면 되는데, Huggingface 의 KoBert 모델을 가져다 쓰려다가 잘 동작하지 않는 듯 해서 시간 날때 다시 보기로 한다.
2) Weaviate 데이터 스키마 구성
영문 테스트 데이터셋은 케글에 있는 데이터를 사용했다.


client.schema.create_class({
"class": "HateSpeech",
"description": "HateSpeech Collection",
"properties": [
{
"dataType": ["text[]"],
"name": "speech",
},
{
"dataType": ["int"],
"name": "clean",
},
],
"vectorizer": "text2vec-contextionary",
})weaviate 에 문장으로 insert 를 하면, 왠지 문장 전체를 벡터화 하는 듯 해서, 테스트 문장을 따로 Tokenize 해서 배열로 넣어보기로 했다.
3) 데이터 삽입
from tensorflow.keras.preprocessing.text import text_to_word_sequence
schemas = []
for idx in range(len(df)):
item = df.iloc[idx]
speech = str(item['comment_text']).strip().lower()
hate = str(item['toxic'])
schemas.append({
"speech" : text_to_word_sequence(speech),
"clean" : 0 if hate == '1' else 1,
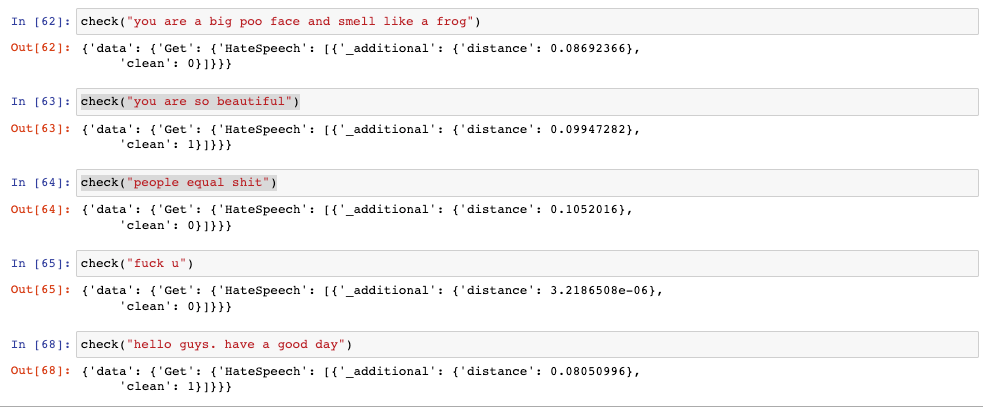
})4) 영문 혐오표현 구분 테스트
clean 값이 0인 경우가 혐오표현으로 판단된 문장이고, 문장을 Tokenize 해서 넣었을때가 weaviate가 자동으로 tokenize 해서 넣주길 바랬을때 보다 정확하게 탐지하는 것을 볼 수 있었다. 이 경우는 Text 를 DB에 넣었을때 상황인데, 이미지를 벡터화 하는 경우는 어떨지 모르겠다.